
“[BodyMouth] makes for a surprisingly musical effect that creates the possibility for brand new genres of artistic expression.”
Gizmodo Magazine
A bespoke interactive “instrument” that produces synthesized movement-reactive vocalizations, made for transmedia playwright Kat Mustatea’s upcoming multimedia theater work Ielele. More information available on Kat’s website.
Intro
BodyMouth is a virtual instrument that produces body position-reactive speech in real-time. Precise position and orientation data streamed from a series of body trackers worn by one or more performers is mapped to a series of adjustable speech parameters such as tongue position, air flow intensity and vocal cord tension. Using a precise series of motions, performers can produce a wide variety of multi-syllabic words with nuanced timing, inflection and pronunciation.
The bespoke instrument was created for transmedia playwright Kat Mustatea’s upcoming experimental theater work, Ielele, which engages with Romanian folklore in the depiction of mythological creatures with augmented bodies and voices. Some more information about the work can be found on Kat’s website.
Sound Processing
BodyMouth uses a custom-made polyphonic refactorization of Pink Trombone, an incredible open-source parametric voice synthesizer created by Neil Thapen as an educational tool. This tool has incredible potential for use in live performance, due to the nuanced control over the voice it affords the user. To make it polyphonic, it had to be refactored using new objects from the Web Audio API, which significantly reduced the processing demands of the software and allowed for multiple voice-processing modules to run simultaneously.
Interfacing with the body trackers, which weren’t designed for use outside a VR context, requires the use of a custom Python script that streams position and orientation per tracker to the voice processor software through a local WebSocket. When the software receives the updated data, it performs a series of calculations on the values to determine information such as the letter being spoken, how far along the pronunciation of the letter the performer is, and whether the letter is currently at the beginning or end of a syllable, which affects the pronunciation of certain letters. Once these values are determined, they are used to index a massive JSON file that contains speech synthesizer values-per-frame for each consonant. These values are fed directly into the synthesizer to be “spoken”, and the process repeats with, presumably, a slightly different set of tracker values.
Scene Editor
A dynamic front-end React UI allows users to create and edit scenes, each with settings for performers and voices. By fine-tuning these settings, a highly-customizable chorus of synthesized voices, each with their own pitch and timbral qualities, can be controlled by a single performer. Voice qualities can range anywhere from a high-pitched soprano to an adolescent male child to a Tuvan throat singer.
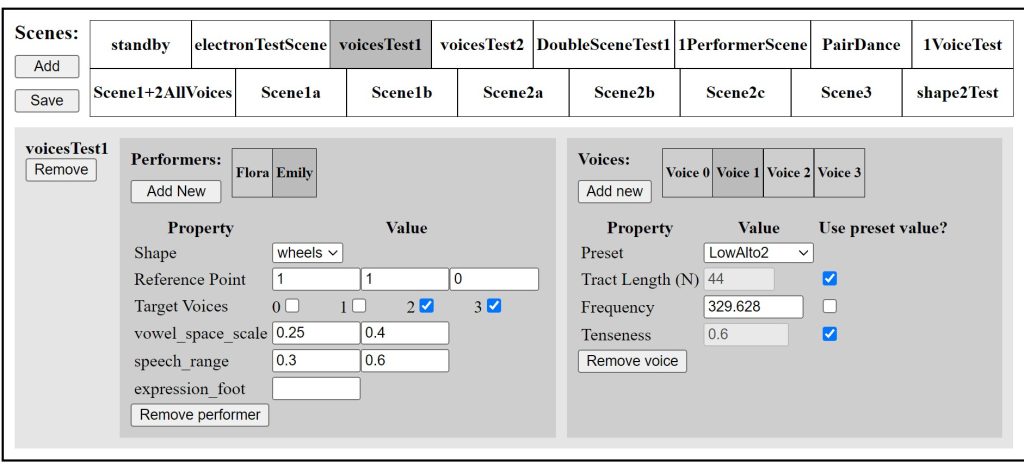
Each scene is a preset containing options for each performer and separate voice. Performer options include reference point, where the performer’s “center” position is relative to the stage, allowing scenes where different performers stand in various locations relative to each other; speech range, which determines the relative size of the motions needed to produce speech; and target voices, which specify which synthesized voice(s) the performer will control in this scene. Voice settings include the length of the vocal tract, which can be shortened to produce “younger”, more “feminine” voices; frequency, which sets the pitch of the voice; and voice tenseness, a timbral quality that ranges from a breathy whispered tone to a harsh, strained one.
By creating sequences of scenes, entire performances can be created easily. In the video seen above, the performance starts with both performers controlling only a single voice. Over the course of the performance, subsequent scenes add in more voices, allowing the harmonic complexity of the “chorus” to increase. Each performer controls 2 voices with semi-improvised motions, leading to interesting indeterminate counterpoint that varies per performance. In the final scene, both performers control all 4 voices at once, creating a powerful contrasting rhythmic unison.
Throughout rehearsals and performance content development sessions, this dynamic UI has proved incredibly helpful for experimenting with various settings for performers and voices
Tech Used:
- HTC Vive body trackers + custom Python script
- Custom voice synthesizer based on Pink Trombone
- Front-end interface and performance state machine built with React/TypeScript and packaged with Electron
Related events/news:
- Upcoming: Barnard Movement Lab residency, June 2024
- Finalist in the 2024 Guthman Musical Instrument Competition.
- Performed in a public preview at ONX Studio, June 2023
- Read about this project and several others on Gizmodo!